2.2 Assessing Model Accuracy
No one statistical learning method dominates all other over all possible data sets. Hence it is an important task to decide that for any given data set which model fits best.
2.2.1 Measuring the Quality of Fit
In the regression setting, the most commonly used measure for quality of fit is mean squared error (MSE), which is given as:
$$MSE = \frac{1}{n} \sum_{i=1}^{n} (y_i - \widehat{f}(x_i))^{2}$$
where $\widehat{f}(x_i)$ is the prediction for the $i$th observation. MSE will be small if the predicted responses are very close to the true responses. While training a model, training MSE is of lesser significance. We should be more interested in test MSE, which is the MSE for the previously unseen test observation not used to train the model. When the test data is available, we can simply compute test MSE and select the model which has the lowest test MSE. In the absence of test data, the basic approach is to simply select a model with the lowest training MSE. Below figure shows the MSE of test and train data for a model.
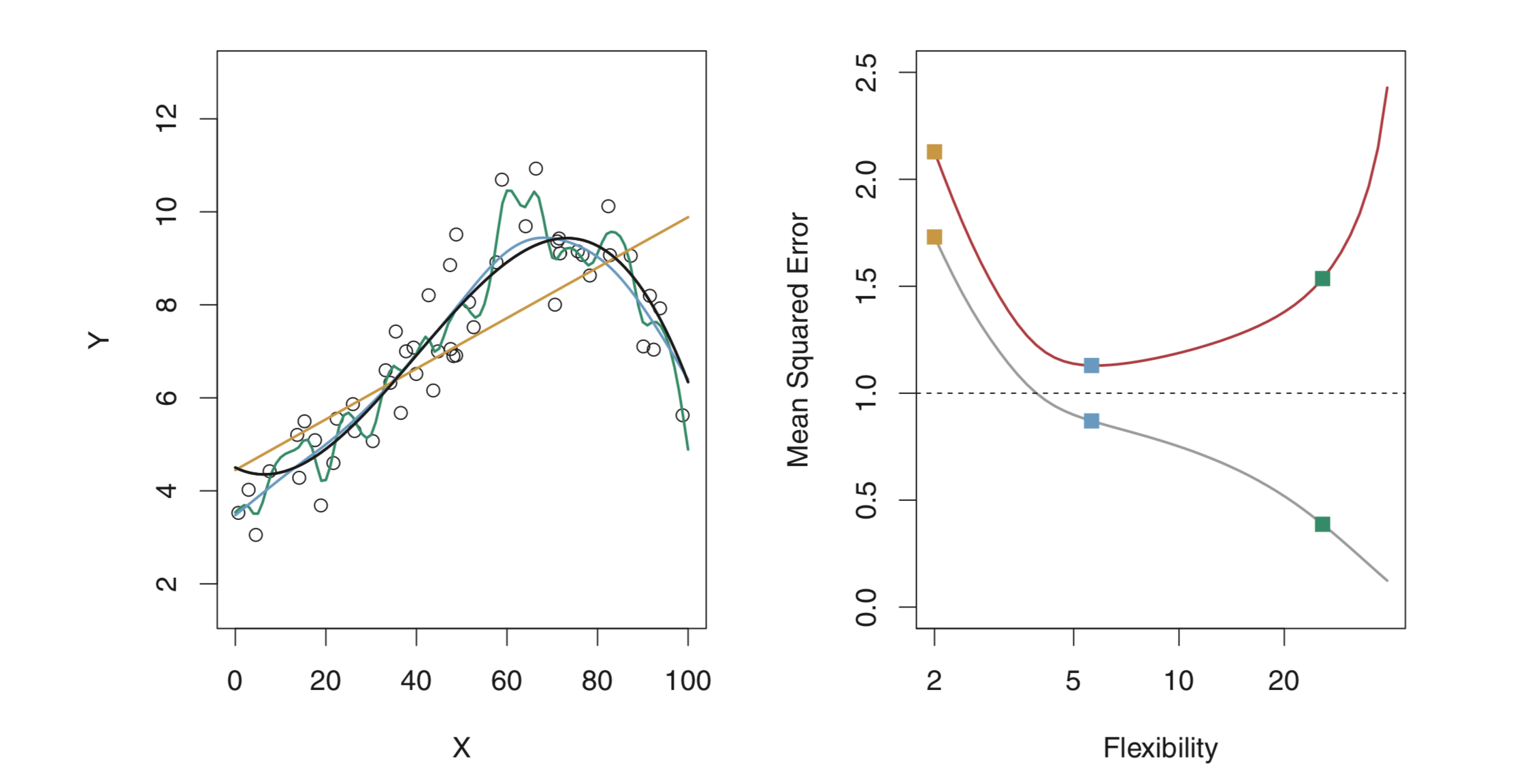
In the right image, the grey curve shows training MSE and the red one test MSE. The horizontal dashed line indicates $Var(\epsilon)$, which is the lowest achievable test MSE amongst all methods. It is to be noted that as we increase flexibility (degree of freedom), training MSE reduces but test MSE tends to increase after a certain point. So the blue curve on the left, which, although has a higher training MSE is the bset fit for the data.
The right hand side figure shows a fundamental property of a statistical model irrespective of the data set or the statistical methods being used. When a small method yields a small training MSE but a large test MSE, we are overfitting the data.
There are various approaches that can be used to find the best model (or find the minimum point) by analysing test MSE. One important method is cross-validation, which is a method for estimating test MSE using the training data.
2.2.2 The Bias-Variance Trade-Off
The expected test MSE for a given value $x_0$ can always be decomposed into the sum of three fundamental quantities: variance of $\widehat{f}(x_0)$, the squared bias of $\widehat{f}(x_0)$ and the variance of the error term $\epsilon$.
$$E(y_0 - \widehat{f}(x_0))^{2} = Var(\widehat{f}(x_0)) + [Bias(\widehat{f}(x_0))]^{2} + Var(\epsilon)$$
Here the notion $E(y_0 - \widehat{f}(x_0))^{2}$ defines the expected test MSE and refers to the average test MSE that would be obtained if we repeatedly estimated $f$ using a large number of training sets ane tested each at $x_0$. The overall expected test MSE can be computed by averaging it over all possible values of $x_0$ in the test set.
In order to minimize the expected test error, we need to select a statistical learning method that simultaneously achieves low variance and low bias.
Variance refers to the amount by which $\widehat{f}$ would change if we estimated it using a different training data. If a statistical method ($\widehat{f})$ has high variance, small change in the training data can result in a largr change in $\widehat{f}$. More flexible statistical methods have higher variance.
Bias refers to the error that is introduced by approximating a real-life problem, which may be extremely complicated, by a much simpler model. Generally, more flexible methods result in less bias.
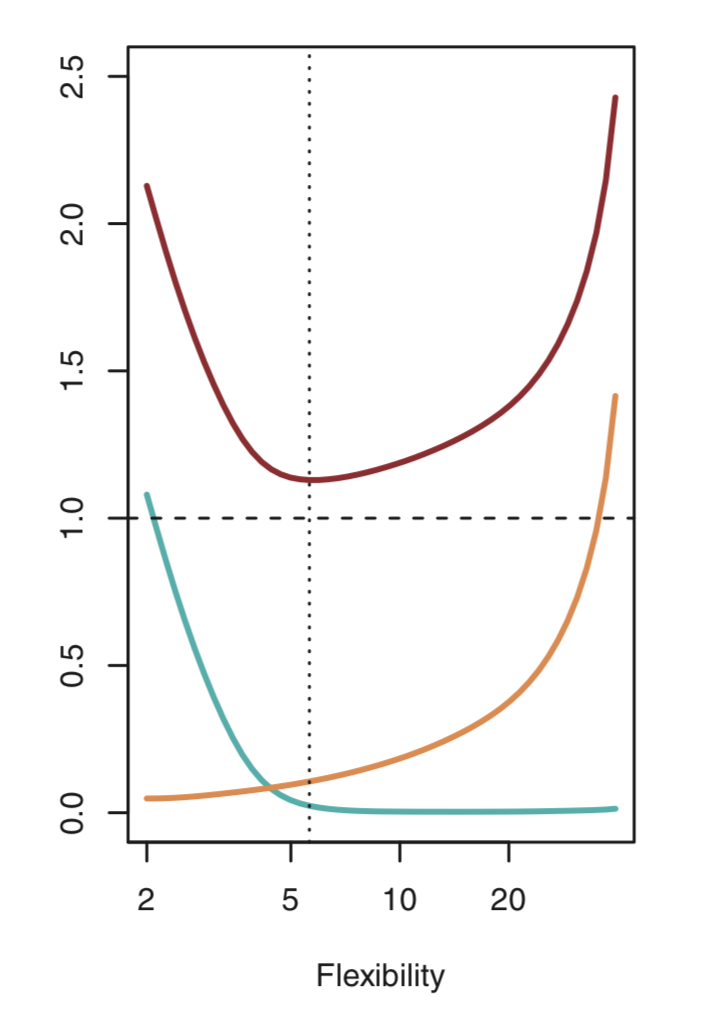
As we use more flixible methods, variance will increase and bias will decrease. As we increase the flexibility of a statistical method, the bias tends to initially decrease faster than the variance increases, and hence the test MSE declines. Below figure illustrates the bias-variance tradeoff (with increasing flexibility) for the example shown above. Blue curve represents the squared bias, orange curve the variance and red curve the test MSE. It should be noted that as we increase the flexibility, bias decreases and variance increases. This phenomenon is referred to as bias-variance tradeoff, as it is easy to obtain a method with extremely low bias but high variance or a method with very low variance but high bias.
2.2.3 The Classification Setting
The most common approach for quantifying the accuracy of the estimate $\widehat{f}$ in the classification setting is the training error rate, defined as the proportion of mistakes that are made if we apply our estimate $\widehat{f}$ to the training observations:
$$\frac{1}{n}\sum_{i=1}^{n} I(y_i \neq \widehat{y_i})$$
where $\widehat{y_i}$ is the predicted class label for the $i$th observation and $I(y_i \neq \widehat{y_i})$ is the indicator variable that equals 1 if $y_i \neq \widehat{y_i}$. Hence, the above equation computes the fraction of incorrect classifications. Similarly, the test error rate associated with the test observations of the form $(x_0, y_0)$ can be calculated as:
$$Ave(I(y_0 \neq \widehat{y_0}))$$
The Bayes Classifier
In the classification setting, the test error rate can be minimized on an average by a simple classifier that assign each observations to the most likely class, given its predictor values. We can simply assign a test observation with predictor value $x_0$ to the class $j$ for which
$$Pr(Y=j \ | \ X = x_0)$$
is largest. This classifier is called as Bayes Classifier. In a two class classifier, Bayes classifier predicts the class 1, if $Pr(Y=1 \ | \ X = x_0) > 0.5$, and class 2 otherwise. The boundary that divides the data set into classes (when probability of being in different classes is equal) is called as the Bayes decision boundary.
The Bayes classifier produces the lowest possible test error rate called as the Bayes error rate. Since the bayes classifier will always choose the class for which the probability is maximum, the error rate at $X = x_ 0$ will be $1 - max_{j}Pr(Y=j \ | \ X=x_0)$. Hence, overall bayes error rate is given as:
$$1 - E(max_{j}Pr(Y=j \ | \ X=x_0)),$$
where exception averages the probability over all possible values in $X$.
K-Nearest Neighbors
For real data, we do not know the conditional distribution of Y given X and hence computing Bayes Classifier is impossible. Many approaches attempt to estimate the conditional distribution of Y given X and then classify a given observation to the calss with highest estimated probability. One such method is called the K-nearest neighbors (KNN) classifier.
Given a positive integer K and a test observation $x_0$, the KNN classifier first identifies the $K$ points in the training data that are closest to $x_0$, represented by $N_0$. It then estimates the conditional probability of class $j$ as the fraction of points in $N_0$ whose response values equal $j$:
$$Pr(Y = j \ | \ X = x_0) = \frac {1}{K} \sum _{i \in N_0}I(y_i = j)$$
Finally, KNN applies Bayes rule and classifies the test observation $x_0$ to the class with the largest probability.
Despite the fact that it is a very simple approach, KNN can often produce classifiers that are surprisingly close to the optimal Bayes classifier. Choice of K has a drastic effect on KNN classifier. Below figure shows the effect of K on KNN decision boundary. When K=1, KNN classifier is highly flexible and find patterns in the data that don’t correspond to the Bayes decision boundary. Hence, lower value of K corresponds to a classifier that has low bias but very high variance. As K grows, the method becomes less flexible and produces a decision boundary that is close to linear. Higher value of K corresponds to a low-variance but high-bias classifier. For KNN, 1\K serves as a measure of flexibility. As K decreases, 1\K increases and hence flexibility increases.
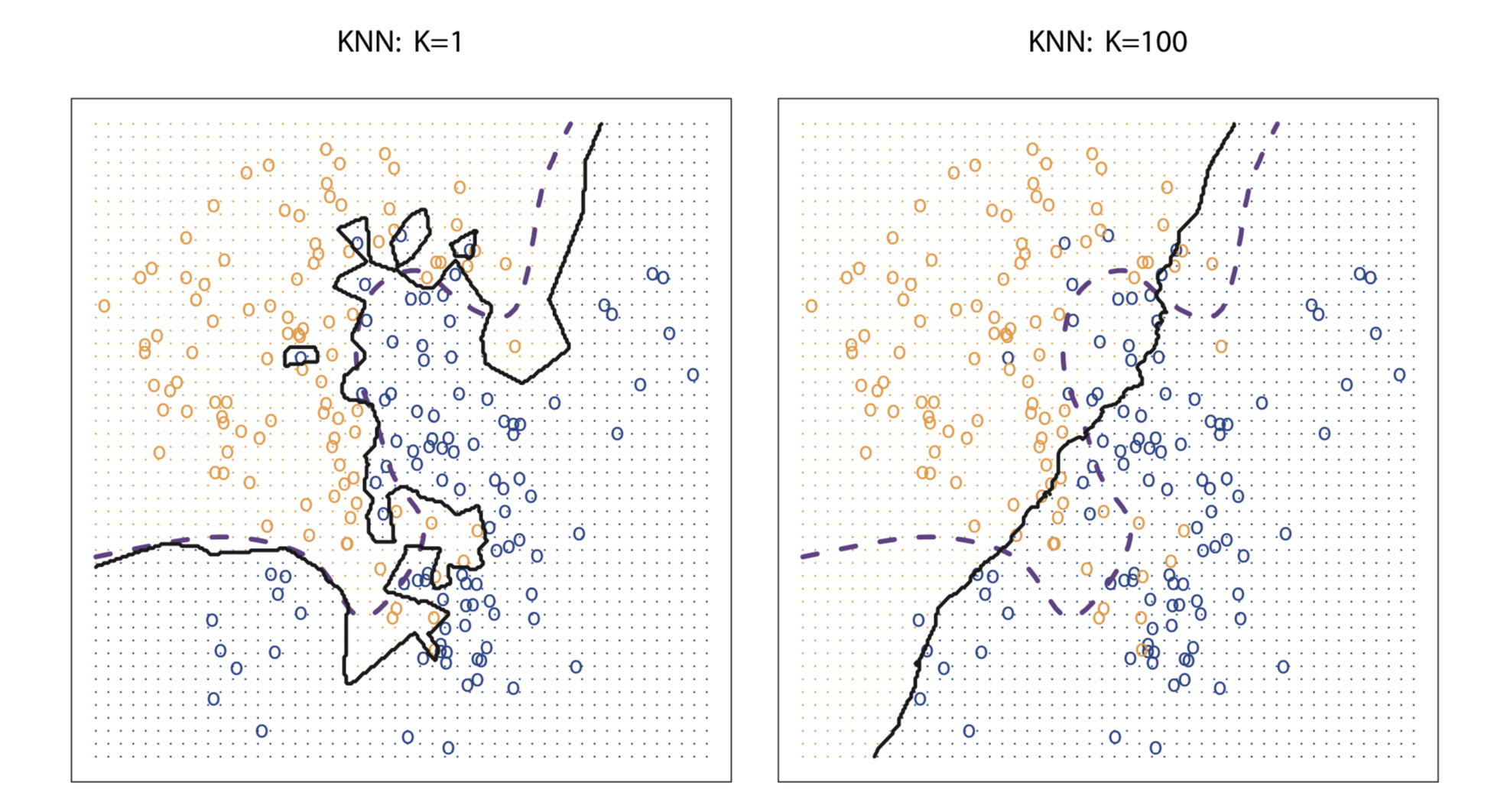
In both the regression and classification settings, choosing the correct level of flexibility is critical to the success of any statistical learning method. The bias-variance tradeoff, and the resulting U-shape in the test error, can make this a difficult task.
2.4 Exercises
Conceptual
Q1. For each of parts (a) through (d), indicate whether we would generally expect the performance of a flexible statistical learning method to be better or worse than an inflexible method. Justify your answer.
(a) The sample size n is extremely large, and the number of predic- tors p is small.
Sol: Better
(b) The number of predictors p is extremely large, and the number of observations n is small.
Sol: Worse
(c) The relationship between the predictors and response is highly non-linear.
Sol: Better
(d) The variance of the error terms, i.e. σ2 = Var(ε), is extremely high.
Sol: Worse, as flixible model will try to fit the error term too.
Q2. Explain whether each scenario is a classification or regression prob- lem, and indicate whether we are most interested in inference or pre- diction. Finally, provide n and p.
(a) We collect a set of data on the top 500 firms in the US. For each firm we record profit, number of employees, industry and the CEO salary. We are interested in understanding which factors affect CEO salary.
Sol: Regression and Inference; n=500, p=3
(b) We are considering launching a new product and wish to know whether it will be a success or a failure. We collect data on 20 similar products that were previously launched. For each product we have recorded whether it was a success or failure, price charged for the product, marketing budget, competition price, and ten other variables.
Sol: Classification and Prediction; n=20, p=13
(c) We are interested in predicting the % change in the USD/Euro exchange rate in relation to the weekly changes in the world stock markets. Hence we collect weekly data for all of 2012. For each week we record the % change in the USD/Euro, the % change in the US market, the % change in the British market, and the % change in the German market.
Sol: Regression and Prediction; n=Weeks in a year, p=3
Q7. The table below provides a training data set containing six observa- tions, three predictors, and one qualitative response variable.
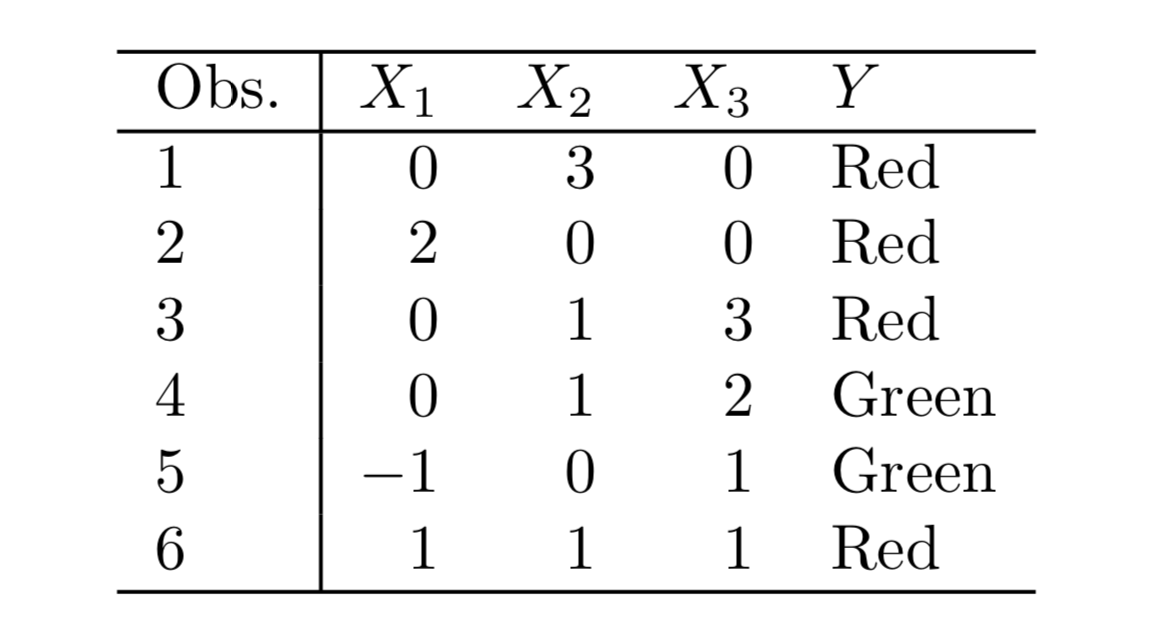
Suppose we wish to use this data set to make a prediction for Y when X1 = X2 = X3 = 0 using K-nearest neighbors.
(a) Compute the Euclidean distance between each observation and thetestpoint,X1 =X2 =X3 =0.
Sol: The Euclidean distance between the test point and the observations is as follows:
{Obs 1: 3, Obs 2: 2, Obs 3: $\sqrt{10}$, Obs 4: $\sqrt{5}$, Obs 5: $\sqrt{2}$, Obs 6: $\sqrt{3}$}
(b) What is our prediction with K = 1? Why?
Sol: The prediction with K=1 is the class of the nearest point which is Green.
(c) What is our prediction with K = 3? Why?
Sol: The three nearest points are : Observations 5,6 and 2 with their classes as Green, Red and Red and hence the prediction will be Red.
(d) If the Bayes decision boundary in this problem is highly non- linear, then would we expect the best value for K to be large or small? Why?
Sol: For highly non-linear Bayes decision boundary, the value of K will be small.
Applied
Q8. This exercise relates to the College data set, which can be found in the file College.csv. It contains a number of variables for 777 different universities and colleges in the US.
import pandas as pd
college = pd.read_csv("data/College.csv")
college.set_index('Unnamed: 0', drop=True, inplace=True)
college.index.names = ['Name']
college.describe()
| Apps | Accept | Enroll | Top10perc | Top25perc | F.Undergrad | P.Undergrad | Outstate | Room.Board | Books | Personal | PhD | Terminal | S.F.Ratio | perc.alumni | Expend | Grad.Rate | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 777.000000 | 777.000000 | 777.000000 | 777.000000 | 777.000000 | 777.000000 | 777.000000 | 777.000000 | 777.000000 | 777.000000 | 777.000000 | 777.000000 | 777.000000 | 777.000000 | 777.000000 | 777.000000 | 777.00000 |
| mean | 3001.638353 | 2018.804376 | 779.972973 | 27.558559 | 55.796654 | 3699.907336 | 855.298584 | 10440.669241 | 4357.526384 | 549.380952 | 1340.642214 | 72.660232 | 79.702703 | 14.089704 | 22.743887 | 9660.171171 | 65.46332 |
| std | 3870.201484 | 2451.113971 | 929.176190 | 17.640364 | 19.804778 | 4850.420531 | 1522.431887 | 4023.016484 | 1096.696416 | 165.105360 | 677.071454 | 16.328155 | 14.722359 | 3.958349 | 12.391801 | 5221.768440 | 17.17771 |
| min | 81.000000 | 72.000000 | 35.000000 | 1.000000 | 9.000000 | 139.000000 | 1.000000 | 2340.000000 | 1780.000000 | 96.000000 | 250.000000 | 8.000000 | 24.000000 | 2.500000 | 0.000000 | 3186.000000 | 10.00000 |
| 25% | 776.000000 | 604.000000 | 242.000000 | 15.000000 | 41.000000 | 992.000000 | 95.000000 | 7320.000000 | 3597.000000 | 470.000000 | 850.000000 | 62.000000 | 71.000000 | 11.500000 | 13.000000 | 6751.000000 | 53.00000 |
| 50% | 1558.000000 | 1110.000000 | 434.000000 | 23.000000 | 54.000000 | 1707.000000 | 353.000000 | 9990.000000 | 4200.000000 | 500.000000 | 1200.000000 | 75.000000 | 82.000000 | 13.600000 | 21.000000 | 8377.000000 | 65.00000 |
| 75% | 3624.000000 | 2424.000000 | 902.000000 | 35.000000 | 69.000000 | 4005.000000 | 967.000000 | 12925.000000 | 5050.000000 | 600.000000 | 1700.000000 | 85.000000 | 92.000000 | 16.500000 | 31.000000 | 10830.000000 | 78.00000 |
| max | 48094.000000 | 26330.000000 | 6392.000000 | 96.000000 | 100.000000 | 31643.000000 | 21836.000000 | 21700.000000 | 8124.000000 | 2340.000000 | 6800.000000 | 103.000000 | 100.000000 | 39.800000 | 64.000000 | 56233.000000 | 118.00000 |
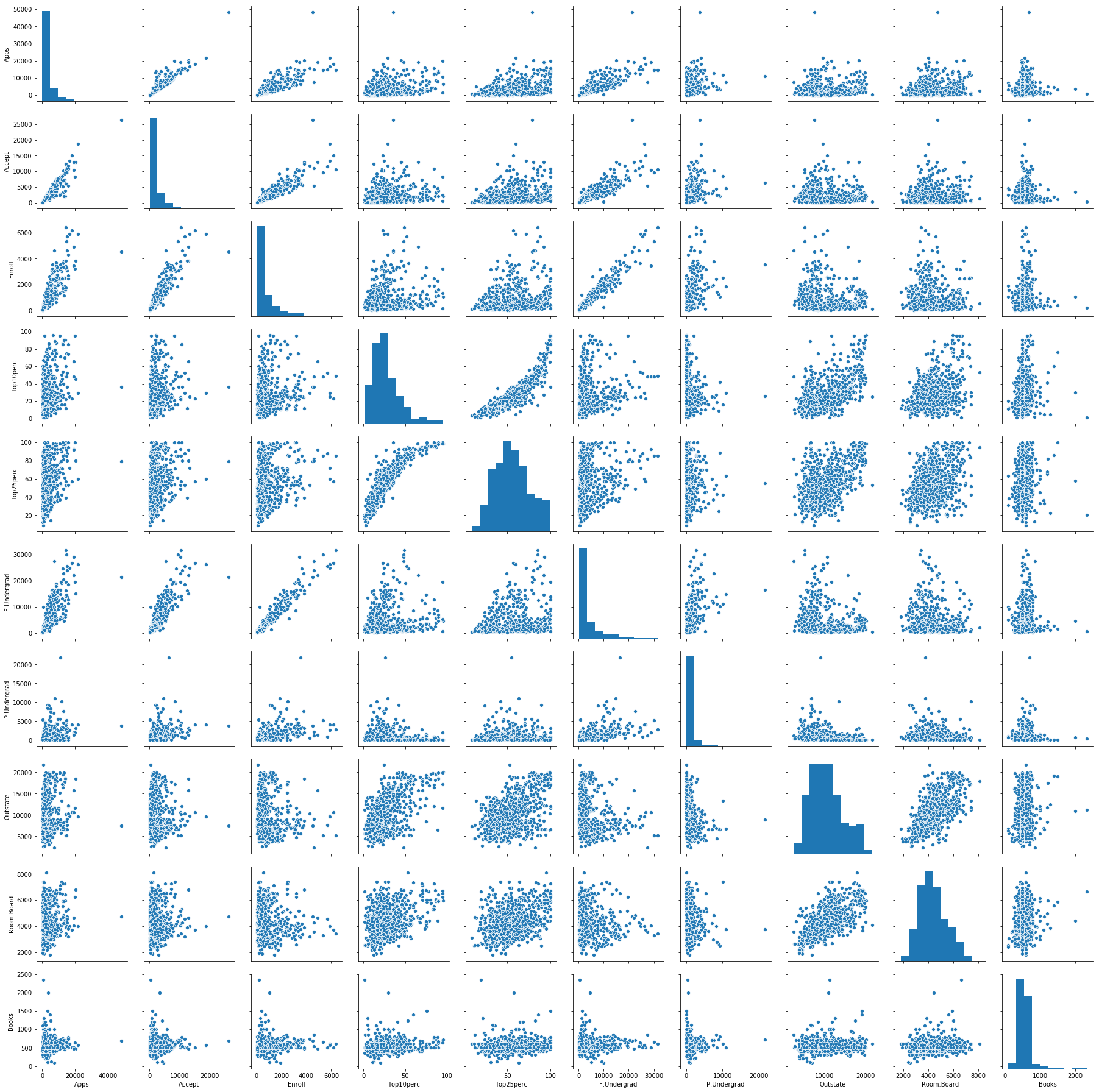
# produce a scatterplot matrix of the first ten columns or variables of the data.
import seaborn as sns
sns.pairplot(college.loc[:, 'Apps':'Books'])
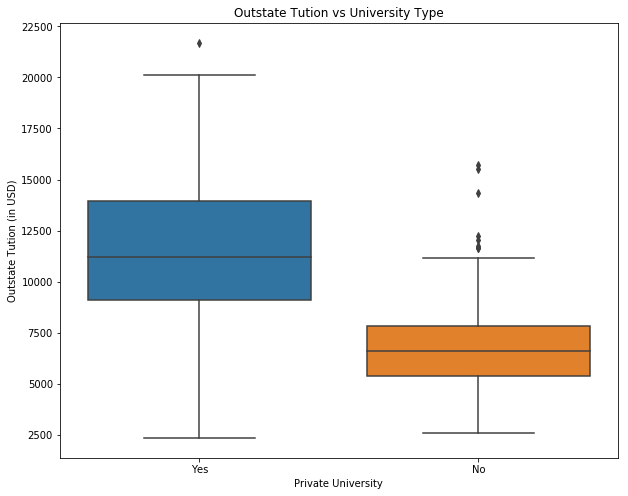
# produce side-by-side boxplots of Outstate versus Private.
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(10, 8))
ax = fig.add_subplot(111)
sns.boxplot(x="Private", y="Outstate", data=college)
ax.set_xlabel('Private University')
ax.set_ylabel('Outstate Tution (in USD)')
ax.set_title('Outstate Tution vs University Type')
plt.show()
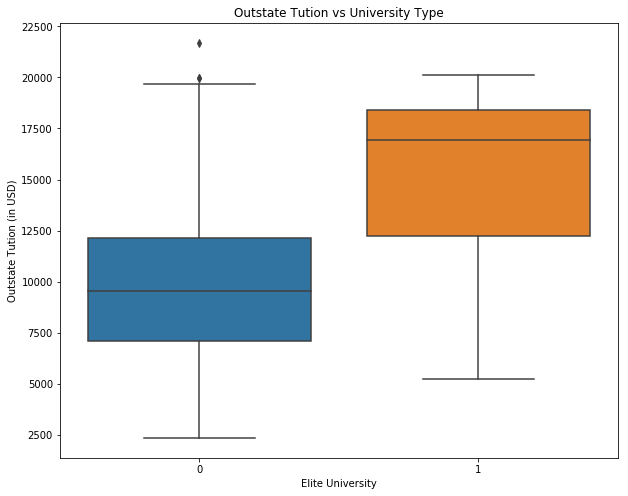
# Create a new qualitative variable, called Elite, by binning the Top10perc variable.
college['Elite'] = 0
college.loc[college['Top10perc'] > 50, 'Elite'] = 1
print("Number of elite universities are: " +str(college['Elite'].sum()))
fig = plt.figure(figsize=(10, 8))
ax = fig.add_subplot(111)
sns.boxplot(x="Elite", y="Outstate", data=college)
ax.set_xlabel('Elite University')
ax.set_ylabel('Outstate Tution (in USD)')
ax.set_title('Outstate Tution vs University Type')
plt.show()
Number of elite universities are: 78
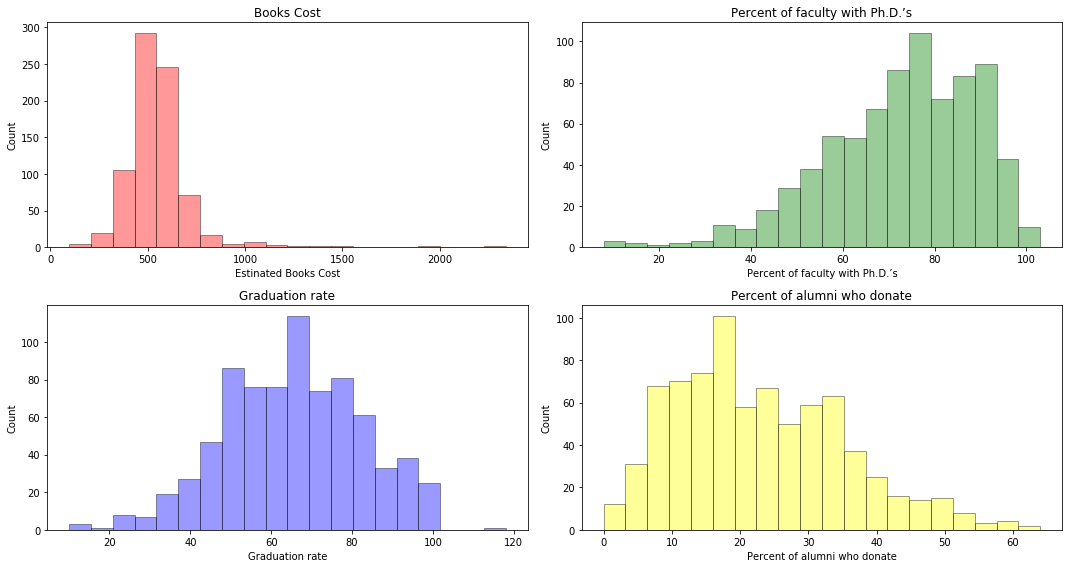
# produce some histograms with differing numbers of bins for a few of the quantitative vari- ables.
college.head()
fig = plt.figure(figsize=(15, 8))
ax = fig.add_subplot(221)
sns.distplot(college['Books'], bins=20, kde=False, color='r', hist_kws=dict(edgecolor='black', linewidth=1))
ax.set_xlabel('Estinated Books Cost')
ax.set_ylabel('Count')
ax.set_title('Books Cost')
ax = fig.add_subplot(222)
sns.distplot(college['PhD'], bins=20, kde=False, color='green', hist_kws=dict(edgecolor='black', linewidth=1))
ax.set_xlabel('Percent of faculty with Ph.D.’s')
ax.set_ylabel('Count')
ax.set_title('Percent of faculty with Ph.D.’s')
ax = fig.add_subplot(223)
sns.distplot(college['Grad.Rate'], bins=20, kde=False, color='blue', hist_kws=dict(edgecolor='black', linewidth=1))
ax.set_xlabel('Graduation rate')
ax.set_ylabel('Count')
ax.set_title('Graduation rate')
ax = fig.add_subplot(224)
sns.distplot(college['perc.alumni'], bins=20, kde=False, color='yellow', hist_kws=dict(edgecolor='black', linewidth=1))
ax.set_xlabel('Percent of alumni who donate')
ax.set_ylabel('Count')
ax.set_title('Percent of alumni who donate')
plt.tight_layout() #Stop subplots from overlapping
plt.show()
Q9. This exercise involves the Auto data set studied in the lab. Make sure that the missing values have been removed from the data.
auto = pd.read_csv("data/Auto.csv")
auto.dropna(inplace=True)
auto = auto[auto['horsepower'] != '?']
auto['horsepower'] = auto['horsepower'].astype(int)
auto.head()
| mpg | cylinders | displacement | horsepower | weight | acceleration | year | origin | name | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 18.0 | 8 | 307.0 | 130 | 3504 | 12.0 | 70 | 1 | chevrolet chevelle malibu |
| 1 | 15.0 | 8 | 350.0 | 165 | 3693 | 11.5 | 70 | 1 | buick skylark 320 |
| 2 | 18.0 | 8 | 318.0 | 150 | 3436 | 11.0 | 70 | 1 | plymouth satellite |
| 3 | 16.0 | 8 | 304.0 | 150 | 3433 | 12.0 | 70 | 1 | amc rebel sst |
| 4 | 17.0 | 8 | 302.0 | 140 | 3449 | 10.5 | 70 | 1 | ford torino |
(a) Which of the predictors are quantitative, and which are qualitative?
Sol: Quantitative: displacement, weight, horsepower, acceleration, mpg
Qualitative: cylinders, year, origin
(b) What is the range of each quantitative predictor?
print("Range of displacement: " + str(auto['displacement'].min()) + " - " + str(auto['displacement'].max()))
print("Range of weight: " + str(auto['weight'].min()) + " - " + str(auto['weight'].max()))
print("Range of horsepower: " + str(auto['horsepower'].min()) + " - " + str(auto['horsepower'].max()))
print("Range of acceleration: " + str(auto['acceleration'].min()) + " - " + str(auto['acceleration'].max()))
print("Range of mpg: " + str(auto['mpg'].min()) + " - " + str(auto['mpg'].max()))
Range of displacement: 68.0 - 455.0
Range of weight: 1613 - 5140
Range of horsepower: 46 - 230
Range of acceleration: 8.0 - 24.8
Range of mpg: 9.0 - 46.6
(c) What is the mean and standard deviation of each quantitative predictor?
auto.describe()[['displacement', 'weight', 'horsepower', 'acceleration', 'mpg']].loc[['mean', 'std']]
| displacement | weight | horsepower | acceleration | mpg | |
|---|---|---|---|---|---|
| mean | 194.411990 | 2977.584184 | 104.469388 | 15.541327 | 23.445918 |
| std | 104.644004 | 849.402560 | 38.491160 | 2.758864 | 7.805007 |
(d) Now remove the 10th through 85th observations. What is the range, mean, and standard deviation of each predictor in the subset of the data that remains?
temp = auto.drop(auto.index[10:85], axis=0)
temp.describe().loc[['mean', 'std', 'min', 'max']]
| mpg | cylinders | displacement | horsepower | weight | acceleration | year | origin | |
|---|---|---|---|---|---|---|---|---|
| mean | 24.374763 | 5.381703 | 187.880126 | 101.003155 | 2938.854890 | 15.704101 | 77.123028 | 1.599369 |
| std | 7.872565 | 1.658135 | 100.169973 | 36.003208 | 811.640668 | 2.719913 | 3.127158 | 0.819308 |
| min | 11.000000 | 3.000000 | 68.000000 | 46.000000 | 1649.000000 | 8.500000 | 70.000000 | 1.000000 |
| max | 46.600000 | 8.000000 | 455.000000 | 230.000000 | 4997.000000 | 24.800000 | 82.000000 | 3.000000 |
(e) Using the full data set, investigate the predictors graphically, using scatterplots or other tools of your choice.
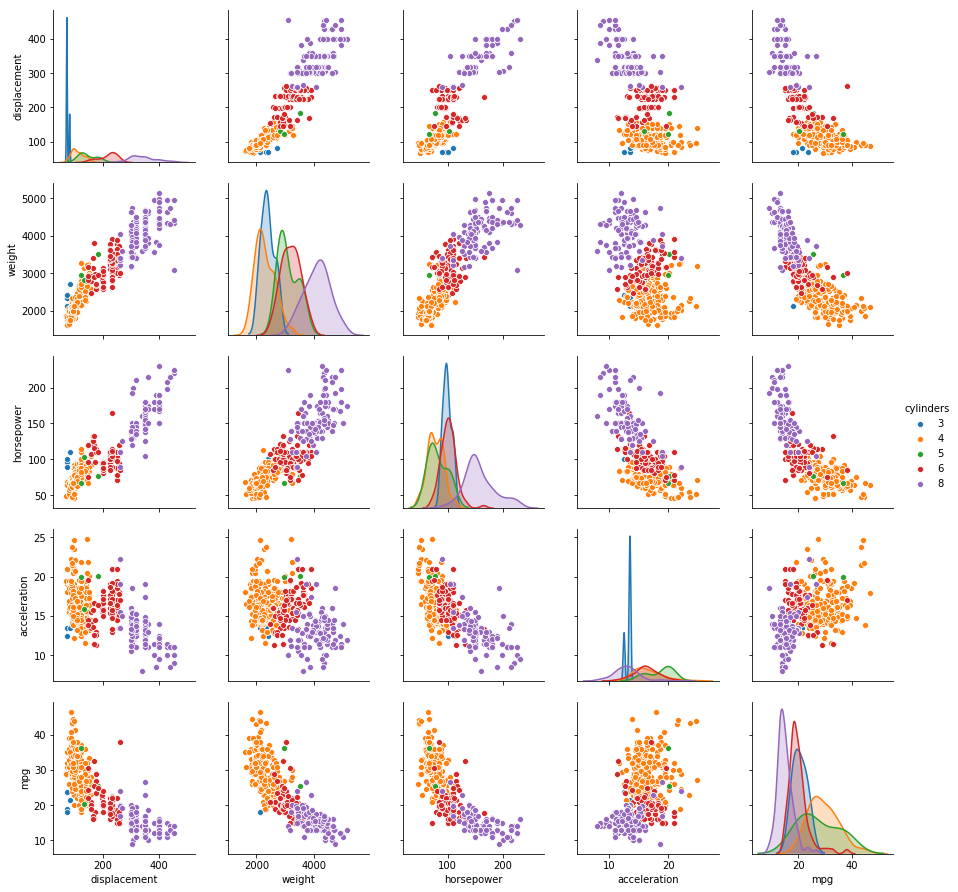
Sol: Two scatterplots of all the quantitative variables segregated by cylinders and origin is shown below. It is evident that vehicles with higher number of cylinders have higher displacement, weight and horsepower, while lower acceleration and mpg. The relationship of mpg with displacement, weight and horsepower is somewhat predictable. Similarly, the relationships of horsepower, weight and displacement with all the other variables follow a trend. Vehicles are somehow distinguishable by origin as well.
# Scatter plot of quantitative variables
sns.pairplot(auto, vars=['displacement', 'weight', 'horsepower', 'acceleration', 'mpg'], hue='cylinders')
sns.pairplot(auto, vars=['displacement', 'weight', 'horsepower', 'acceleration', 'mpg'], hue='origin')
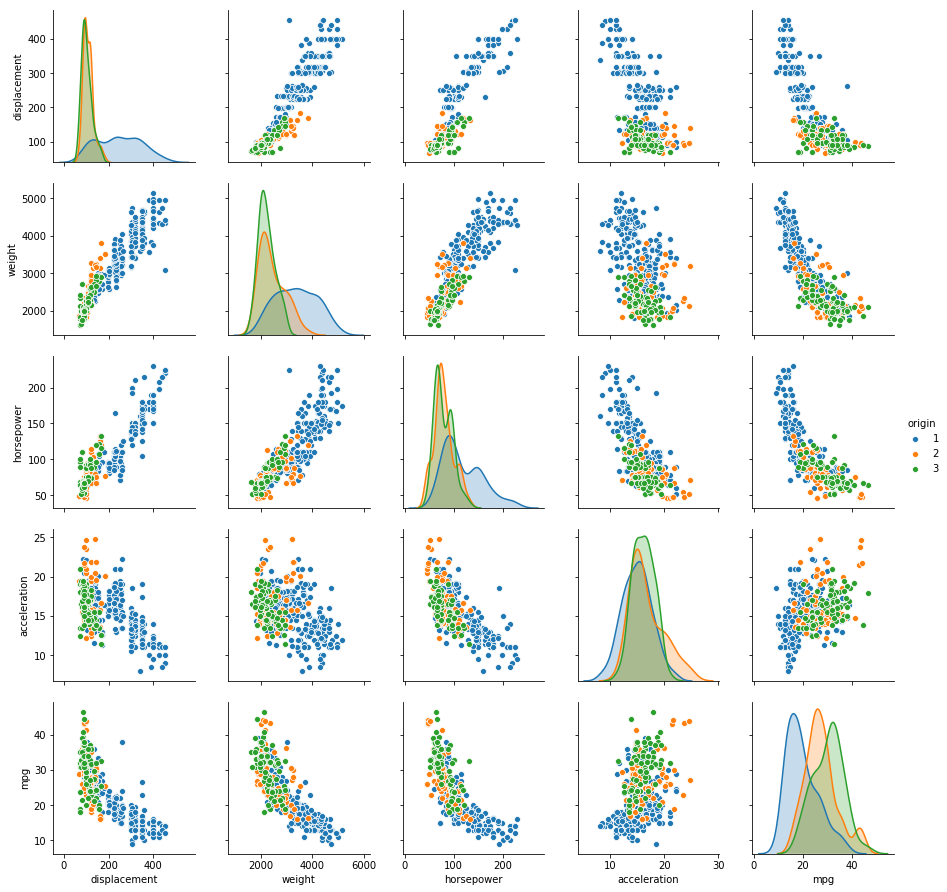
(f) Suppose that we wish to predict gas mileage (mpg) on the basis of the other variables. Do your plots suggest that any of the other variables might be useful in predicting mpg? Justify your answer.
Sol: From the plot, it is evident that displacement, weight and horsepower can play a significant role in the prediction of mpg. As displacement is highly correlated with weight and horsepower, we can pick any one of them for the prediction. Origin and cylinders can also be used for prediction.
Q10. This exercise involves the Boston housing data set.
(a) How many rows are in this data set? How many columns? What do the rows and columns represent?
from sklearn.datasets import load_boston
boston = load_boston()
print("(Rows, Cols): " +str(boston.data.shape))
print(boston.DESCR)
(Rows, Cols): (506, 13)
Boston House Prices dataset
===========================
Notes
------
Data Set Characteristics:
:Number of Instances: 506
:Number of Attributes: 13 numeric/categorical predictive
:Median Value (attribute 14) is usually the target
:Attribute Information (in order):
- CRIM per capita crime rate by town
- ZN proportion of residential land zoned for lots over 25,000 sq.ft.
- INDUS proportion of non-retail business acres per town
- CHAS Charles River dummy variable (= 1 if tract bounds river; 0 otherwise)
- NOX nitric oxides concentration (parts per 10 million)
- RM average number of rooms per dwelling
- AGE proportion of owner-occupied units built prior to 1940
- DIS weighted distances to five Boston employment centres
- RAD index of accessibility to radial highways
- TAX full-value property-tax rate per $10,000
- PTRATIO pupil-teacher ratio by town
- B 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town
- LSTAT % lower status of the population
- MEDV Median value of owner-occupied homes in $1000's
:Missing Attribute Values: None
:Creator: Harrison, D. and Rubinfeld, D.L.
This is a copy of UCI ML housing dataset.
http://archive.ics.uci.edu/ml/datasets/Housing
This dataset was taken from the StatLib library which is maintained at Carnegie Mellon University.
The Boston house-price data of Harrison, D. and Rubinfeld, D.L. 'Hedonic
prices and the demand for clean air', J. Environ. Economics & Management,
vol.5, 81-102, 1978. Used in Belsley, Kuh & Welsch, 'Regression diagnostics
...', Wiley, 1980. N.B. Various transformations are used in the table on
pages 244-261 of the latter.
The Boston house-price data has been used in many machine learning papers that address regression
problems.
**References**
- Belsley, Kuh & Welsch, 'Regression diagnostics: Identifying Influential Data and Sources of Collinearity', Wiley, 1980. 244-261.
- Quinlan,R. (1993). Combining Instance-Based and Model-Based Learning. In Proceedings on the Tenth International Conference of Machine Learning, 236-243, University of Massachusetts, Amherst. Morgan Kaufmann.
- many more! (see http://archive.ics.uci.edu/ml/datasets/Housing)
(b) Make some pairwise scatterplots of the predictors (columns) in this data set. Describe your findings.
Sol: Pairwise scatterplot of nitric oxides concentration vs weighted distances to five Boston employment centres shows that as distance decreases, the concentration of nitrous oxide increases.
df_boston = pd.DataFrame(boston.data, columns=['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX',
'PTRATIO', 'B', 'LSTAT'])
sns.pairplot(df_boston, vars=['NOX', 'DIS'])
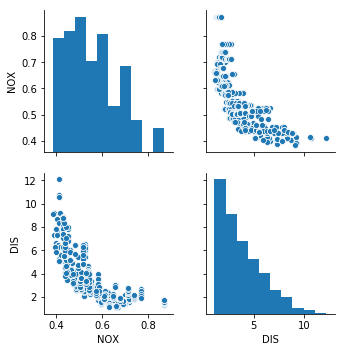
(c) Are any of the predictors associated with per capita crime rate? If so, explain the relationship.
Sol: As most of the area has crime rate less than 20%, we will analyze the scatterplot for those areas only.
fig = plt.figure(figsize=(15, 8))
ax = fig.add_subplot(111)
sns.distplot(df_boston['CRIM'], bins=20, kde=False, color='r', hist_kws=dict(edgecolor='black', linewidth=1))
ax.set_xlabel('Crime Rate')
ax.set_ylabel('Count')
ax.set_title('Crime Rate Histogram')
Text(0.5,1,'Crime Rate Histogram')
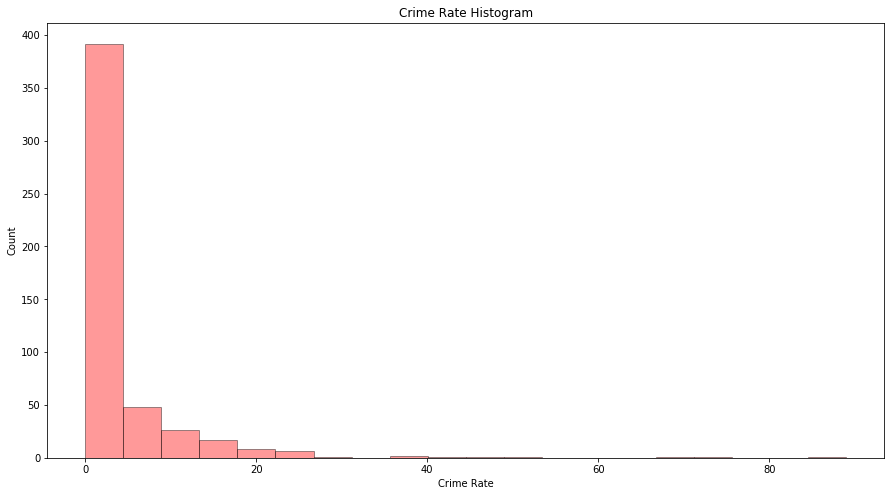
temp = df_boston[df_boston['CRIM'] <= 20]
sns.pairplot(temp, y_vars=['CRIM'], x_vars=['NOX', 'RM', 'AGE', 'DIS', 'LSTAT'])

(d) Do any of the suburbs of Boston appear to have particularly high crime rates? Tax rates? Pupil-teacher ratios? Comment on the range of each predictor.
print("Count of suburbs with higher crime rate: " + str(df_boston[df_boston['CRIM'] > 20].shape[0]))
print("Count of suburbs with higher tax rate: " + str(df_boston[df_boston['TAX'] > 600].shape[0]))
print("Count of suburbs with higher pupil-teacher ratio: " + str(df_boston[df_boston['PTRATIO'] > 20].shape[0]))
Count of suburbs with higher crime rate: 18
Count of suburbs with higher tax rate: 137
Count of suburbs with higher pupil-teacher ratio: 201
(e) How many of the suburbs in this data set bound the Charles river?
print("Suburbs bound the Charles river: " + str(df_boston[df_boston['CHAS'] == 1].shape[0]))
Suburbs bound the Charles river: 35
(f) What is the median pupil-teacher ratio among the towns in this data set?
print("Median pupil-teacher ratio is: " + str(df_boston['PTRATIO'].median()))
Median pupil-teacher ratio is: 19.05
(h) In this data set, how many of the suburbs average more than seven rooms per dwelling? More than eight rooms per dwelling?
print("Suburbs with average more than 7 rooms per dwelling: " + str(df_boston[df_boston['RM'] > 7].shape[0]))
print("Suburbs with average more than 7 rooms per dwelling: " + str(df_boston[df_boston['RM'] > 8].shape[0]))
Suburbs with average more than 7 rooms per dwelling: 64
Suburbs with average more than 7 rooms per dwelling: 13